“SETI@home:优化程序”的版本间差异
Arthur200000(讨论 | 贡献) 小 (重π) |
Arthur200000(讨论 | 贡献) |
||
| (未显示2个用户的72个中间版本) | |||
| 第1行: | 第1行: | ||
| + | ←回到[[SETI@home]] | ||
| + | ---- | ||
| + | {{Volatile|Arthur200000|百度网盘失效,请暂时直接使用官方链接寻找最新版本。}} | ||
SETI优化程序是一系列在保证结果准确度的前提下利用[[Wikipedia:zh:CPU指令集]]加快运算速度的程序。 | SETI优化程序是一系列在保证结果准确度的前提下利用[[Wikipedia:zh:CPU指令集]]加快运算速度的程序。 | ||
| − | + | '''Lunatics Unified Installer''' 是由 '''Lunatics Team''' 制作的 [[SETI@home]] 优化安装程序。集成了 Astropulse、MultiBeam 的最新优化程序及 GPU 程序,傻瓜式安装,为用户提供向导式的安装优化计算程序,简化了之前手动安装优化程序的麻烦。 | |
| − | '''Lunatics Unified Installer''' 是由 '''Lunatics Team''' 制作的 [[SETI@home]] 优化安装程序。集成了 Astropulse、MultiBeam | + | =='''安装向导'''== |
| + | {{Warning|目前的混合安装包只适合Windows系统。如果你使用其它操作系统,请至作者网站寻找。}} | ||
| + | {{Tip|为了节省资源,安装优化程序会关闭图形显示。如果你十分喜欢屏保画面或者经常利用屏保宣传此项目,请勿安装优化程序。}} | ||
| + | 1. 访问 [http://lunatics.kwsn.info/ Lunatics Team] 的优化程序[http://lunatics.kwsn.info/index.php?module=Downloads 下载页面],下载对应的 Lunatics' Unified Installer 版本。<br>'''如果找不到优化,可以尝试CPU优化作者arkayn的网站:http://www.arkayn.us/forum''' | ||
| + | *请直接使用[http://pan.baidu.com/share/link?shareid=414396&uk=3207560304 百度网盘]下载。 | ||
| + | (如不能下载,请联本站论坛管理员或版主) | ||
| + | |||
| + | 2. '''选择退出boinc manager并勾选“退出boinc manager 的同时停止运行科学计算程序”。'''然后运行 Lunatics Unified Installer,根据被安装计算机的特性选择有效的指令集选项。 | ||
| + | <gallery> | ||
| + | Image:Lunatics_Unified_Installer_CPU.png|安装时的CPU选项卡,用户可根据被安装计算机的CPU特性选择有效的指令集选项,v0.41中不支持的选项已经屏蔽(灰色)并且会自动选择最佳的CPU优化。 | ||
| + | Image:Lunatics_Unified_Installer_ATI.png|安装时的ATI选项卡,用户可根据被安装计算机的ATI显卡型号选择,程序中已经说明了选择方法。 | ||
| + | Image:Lunatics_Unified_Installer_NV.png|安装时的nVidia选项卡,用户可根据被安装计算机的nVidia显卡型号选择,有关的Multibeam-CUDA选择方法请参阅[[#关于CUDA程序|CUDA程序说明]],上方的AP OpenCL可以考虑开启。 | ||
| + | <!-- 留个空给Intel⑨ 显卡,TODO v0.43 Windows Classical Screenshot--> | ||
| + | <!-- Image:Lunatics_Unified_Installer_IntelGPU.png|安装时的Intel GPU选项卡,用户可根据被安装计算机的Intel集成显卡型号选择。--> | ||
| + | </gallery> | ||
| + | |||
| + | ==版本信息== | ||
| + | 目前版本为 v0.44/v0.45b;自动安装器仅支持 Windows 平台,其他平台可以手动下载程序和app_info到[[#GPU 计算程序]]提到的目录。'''目前的版本已经支持了自动探测CPU指令集,但是显卡型号需要自行选择。''' | ||
| + | SETI@home v8 更新后必须使用大于 0.44 版本的优化程序。 | ||
| − | + | 具体的各优化程序版本: | |
| − | [[ | + | *CPU |
| − | + | **Astropulse v7:需要 CPU 支持 SSE 或者 SSE3 指令集,基于原r555/r557…r1797制作。 | |
| + | **Multibeam v8(CPU):需要 CPU 支持 SSE 或以上的指令集。 | ||
| + | *CUDA:Multibeam(x41zi) | ||
| + | **需要支持 nVidia CUDA 的 GPU,驱动程序需要支持 CUDA 2.2 及版本在 185.85 以上(建议使用目前最新版本驱动),可用显存至少有 200~235 MB。原则上,这需要512[[Wikipedia:zh:MiB|MiB]]以上的显存;当然你也可以使用一个256MiB的显卡,为了尽量节省显存,你应该关闭一些显示效果,例如 Windows Vista 或以上版本的 [[Wikipedia:Aero|Aero]] 效果(并且可以尝试降低颜色深度和刷新率,例如1024*768 16bit@60Hz)。这时,你应该时刻注意[[Wikipedia:zh:GPU-Z|GPU-Z]]以及BOINC 管理器的窗口,以确认计算程序获得了足够的显存。显存不足的征兆有二: | ||
| + | #对于BOINC:一个任务开始,运行极短时间(几秒钟)就换一个执行,原先的显示等待或者调度等待。 | ||
| + | #对于GPU-Z:传感器显示显存使用上升后立即下降。 | ||
| + | 如果你的尝试一再失败,请考虑不进行这个CUDA计算。{{Tip|出现问题时可以尝试重启,一般会恢复。}} | ||
| + | :*请阅读:[[#关于CUDA程序]]、[[#CUDA程序设置]]两章以最大化利用您的系统资源;参阅ReadMe_x41zi.txt。 | ||
| + | *OpenCL | ||
| + | *AstroPulse NVidia:请参阅附带的ReadMe_AstroPulse_OpenCL_NV.txt文件。 | ||
| + | *Multibeam+AstroPulse ATI:需要ATI HD4000以上的GPU;一般分为 HD5(HD5000+)和普通两个版本。 | ||
| + | *Multibeam+AstroPulse Intel:需要 OpenCL 1.2+;参阅ReadMe_AstroPulse_OpenCL_Intel.txt、ReadMe_Multibeam_OpenCL_Intel.txt。 | ||
| − | + | '''当留出一个CPU核心时,显卡计算程序可以获得更高的处理效率。当然,在任务管理器中手动将该程序优先级提升至“高”也有类似的效果。'''CUDA 程序有自带设置优先级的功能,见下方说明。 | |
| − | |||
| − | + | ===关于指令集=== | |
| − | + | 原则上 CPU 指令集越高越好,但是部分 AMD CPU 的 AVX 性能不如 SSE4.2 性能。由于 AVX 使用额外寄存器增加发热,CPU 可能反而会降频工作。建议测试后选择。 | |
| − | + | ||
| − | + | ===关于CUDA程序=== | |
| − | + | v0.41 版本的综合安装包内提供了多种CUDA程序,选择判据如下: | |
| − | + | #CUDA 2.3(最低驱动190.38):仅用于老显卡,几乎是万能的。推荐用于8xxx 系列,9xxx 系列,GTX 200 系列等不支持费米/开普勒架构的小显存版本(256MiB)显卡。'''不兼容费米/开普勒架构。''' | |
| − | + | #CUDA 3.2(最低驱动263.06):“存货”,完全万能,支持费米/开普勒架构。推荐用于8xxx 系列,9xxx 系列,GTX 200 系列等显卡的较大显存版本(300+MiB)。 | |
| − | + | #CUDA 4.2(最低驱动301.48):推荐用于费米架构(GTX 4xx~GTX 5xx),可以获得极大的性能提升。 | |
| − | * | + | #CUDA 5.0(最低驱动306.23):推荐用于开普勒/麦克斯韦架构(GTX 6xx+),可以获得极大的性能提升。 |
| − | * | + | 在优化程序下载网页也提供这种CUDA优化: |
| − | * | + | #CUDA 2.2(最低驱动185.85):“老存货”,为无法更新驱动的用户设计。'''不兼容费米/开普勒架构。''' |
| − | + | ||
| − | + | == 调优配置 == | |
| + | 本项目的运算程序和数据文件位于 <tt>'''<BOINC数据目录>'''/projects/setiathome.berkeley.edu</tt> 内。请首先阅读[[GPU 计算#性能考量]]。 | ||
| + | ===CUDA程序设置=== | ||
| + | x41zc或以上的CUDA程序在其安装目录会创建一个mbcuda.cfg,用于自定义程序。'''(用记事本或类似程序打开编辑)''' | ||
| + | |||
| + | ====参数==== | ||
| + | *processpriority 进程优先级,有'belownormal' (默认), 'normal', 'abovenormal'(推荐), or 'high'(刷分用)四个选项。 | ||
| + | *pfblockspersm 每个处理器的搜索运行数量,取值1~16,CUDA3.2或更低版本默认为1,CUDA4.0默认为4,高端卡建议适当加大。 | ||
| + | *pfperiodsperlaunch 每次内核启动后信号搜索的最大周期,取值1~1000,默认为100 | ||
| + | |||
| + | 文件中的分号“;”会将内容加载为注释(即不用),删除后就会激活。 | ||
| + | |||
| + | 对于CUDA3.2以上的程序,允许自定义每个GPU的参数,其中[mbcuda]表示通用设置,形如[bus'''x'''slot'''y''']表示以下的一段是X控制器Y槽上面的显卡。 | ||
| − | + | ===OpenCL程序设置=== | |
| + | 可以通过编辑 <tt>cmdline_'''程序名代号'''.txt</tt> 指定命令行参数来改变优先级和其他的计算细节。要让 OpenCL 各程序使用高优先级运行,只需在这些文件中写入 <tt>-hp</tt>。 | ||
| − | + | OpenCL 程序有类似 CUDA 的搜索并行度设置,请参阅README给出的例子设置命令行。 | |
| − | |||
| − | + | '''勘误''':Intel 的 MB 程序对于高端卡有 oclfft_tune_wg 设置 512 的建议,实际上最大只能使用 256。 | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | + | =='''其他'''== | |
*Lunatics Team 发布了 '''AstroPulse ATI/AMD 纯GPU 和 GPU+CPU 混合优化程序(Win)''',[http://www.equn.com/forum/thread-28870-1-1.html 点击这里查看详情]。 | *Lunatics Team 发布了 '''AstroPulse ATI/AMD 纯GPU 和 GPU+CPU 混合优化程序(Win)''',[http://www.equn.com/forum/thread-28870-1-1.html 点击这里查看详情]。 | ||
*Lunatics Team 发布了 '''MultiBeam ATI OpenCL 优化程序发布(Win)''',[http://www.equn.com/forum/thread-30252-1-1.html 点击这里查看详情]。 | *Lunatics Team 发布了 '''MultiBeam ATI OpenCL 优化程序发布(Win)''',[http://www.equn.com/forum/thread-30252-1-1.html 点击这里查看详情]。 | ||
| − | == | + | ==附录I:使用Intel显卡计算== |
| − | + | '''现有的优化程序版本(v0.43)和官方服务器均已经在安装向导中提供使用 Intel 显卡的选项,无需冒险这么处理。''' | |
| − | + | {{Warning|由于计算程序从[[SETI@home/AstroPulse Beta|测试项目]]提取,且存在微小的版本不同问题,不排除有验证无效或计算错误(爆包)的可能。}} | |
| + | 用法: | ||
| + | #加入[[SETI@home/AstroPulse Beta|SETI@home beta]]项目,使用支持OpenCL的Intel GPU下载一个WU。(需要BOINC7.0+) | ||
| + | #进入BOINC的数据目录(一般在AppData一类的位置),进入Project子目录,找到带有Intel GPU字样的程序并复制到SETI@home的目录。 | ||
| + | #尝试改写app_info.xml(如果你先安装了优化程序的话): | ||
| + | [http://www.equn.com/forum/thread-37726-1-1.html 代码]{{Warning|目前可能存在一个问题,即优化程序会删除一些其他的计算程序,可以自己尝试删除该特性。}}{{Tip|已知优化程序会在Windows的运行中新建一个命令,这可能是问题的突破口。}} | ||
| + | <big><center>这样就完成了!</center></big> | ||
| + | ===问题处理=== | ||
| + | 为了防止你的程序被删除,可以尝试事先复制走优化程序(不需要目录下其他文件夹,只要孤立的文件——必须包括app_info),卸载优化再放回。 | ||
| + | |||
| + | ==附录II:进一步提高处理效率== | ||
| + | 如果你有空有耐心敢尝试,你可以让自己的处理效率更高一点。 | ||
| + | |||
| + | ===自行编译程序=== | ||
| + | # 下载源代码:http://lunatics.kwsn.net/index.php?module=Downloads;catd=2 | ||
| + | # 准备编译工具,你主要需要gcc,g++,cmake以及各个GNU lib(Windows下可以使用MinGW和CMake,根据报错log找需要的组件。) | ||
| + | # 进行编译,使用g++或gcc时你可以加入参数 <tt>-march=native -mtune=native -O3</tt> 自动利用CPU检测到的指令集并进行优化。对于clang编译器,<tt>-O4</tt> 会带来更高效率。 | ||
| + | #* 理论上使用 <tt>-Ofast</tt> 效率更高(主要是因为 <tt>-ffast-math</tt> 去除少量检查后带来的浮点提升),然而可能导致计算错误。 | ||
| + | #* 使用 <tt>-flto</tt> 可能换来一定程度的性能提升。使用 <tt>-fpgo</tt> 可令程序编译完后运行一次记录常用函数并使编译器重点优化。 | ||
2019年1月8日 (二) 22:06的最新版本
←回到SETI@home
| 当前页面或段落的信息可能过时 当前页面或段落描述的信息变化较快,可能误导读者,希望了解相关内容的Wiki用户协助编辑。
用户 Arthur200000 给出的意见是:百度网盘失效,请暂时直接使用官方链接寻找最新版本。 。 其他用户若有异议,请前往讨论:SETI@home:优化程序发表见解。 欢迎无wiki账号的用户到论坛的Wiki系统讨论区(注册)参与讨论。 |
SETI优化程序是一系列在保证结果准确度的前提下利用Wikipedia:zh:CPU指令集加快运算速度的程序。 Lunatics Unified Installer 是由 Lunatics Team 制作的 SETI@home 优化安装程序。集成了 Astropulse、MultiBeam 的最新优化程序及 GPU 程序,傻瓜式安装,为用户提供向导式的安装优化计算程序,简化了之前手动安装优化程序的麻烦。
安装向导
1. 访问 Lunatics Team 的优化程序下载页面,下载对应的 Lunatics' Unified Installer 版本。
如果找不到优化,可以尝试CPU优化作者arkayn的网站:http://www.arkayn.us/forum
- 请直接使用百度网盘下载。
(如不能下载,请联本站论坛管理员或版主)
2. 选择退出boinc manager并勾选“退出boinc manager 的同时停止运行科学计算程序”。然后运行 Lunatics Unified Installer,根据被安装计算机的特性选择有效的指令集选项。
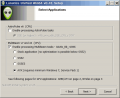
安装时的CPU选项卡,用户可根据被安装计算机的CPU特性选择有效的指令集选项,v0.41中不支持的选项已经屏蔽(灰色)并且会自动选择最佳的CPU优化。
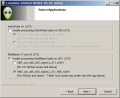
安装时的ATI选项卡,用户可根据被安装计算机的ATI显卡型号选择,程序中已经说明了选择方法。
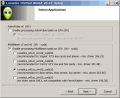
安装时的nVidia选项卡,用户可根据被安装计算机的nVidia显卡型号选择,有关的Multibeam-CUDA选择方法请参阅CUDA程序说明,上方的AP OpenCL可以考虑开启。



版本信息
目前版本为 v0.44/v0.45b;自动安装器仅支持 Windows 平台,其他平台可以手动下载程序和app_info到#GPU 计算程序提到的目录。目前的版本已经支持了自动探测CPU指令集,但是显卡型号需要自行选择。
SETI@home v8 更新后必须使用大于 0.44 版本的优化程序。
具体的各优化程序版本:
- CPU
- Astropulse v7:需要 CPU 支持 SSE 或者 SSE3 指令集,基于原r555/r557…r1797制作。
- Multibeam v8(CPU):需要 CPU 支持 SSE 或以上的指令集。
- CUDA:Multibeam(x41zi)
- 对于BOINC:一个任务开始,运行极短时间(几秒钟)就换一个执行,原先的显示等待或者调度等待。
- 对于GPU-Z:传感器显示显存使用上升后立即下降。
如果你的尝试一再失败,请考虑不进行这个CUDA计算。
- OpenCL
- AstroPulse NVidia:请参阅附带的ReadMe_AstroPulse_OpenCL_NV.txt文件。
- Multibeam+AstroPulse ATI:需要ATI HD4000以上的GPU;一般分为 HD5(HD5000+)和普通两个版本。
- Multibeam+AstroPulse Intel:需要 OpenCL 1.2+;参阅ReadMe_AstroPulse_OpenCL_Intel.txt、ReadMe_Multibeam_OpenCL_Intel.txt。
当留出一个CPU核心时,显卡计算程序可以获得更高的处理效率。当然,在任务管理器中手动将该程序优先级提升至“高”也有类似的效果。CUDA 程序有自带设置优先级的功能,见下方说明。
关于指令集
原则上 CPU 指令集越高越好,但是部分 AMD CPU 的 AVX 性能不如 SSE4.2 性能。由于 AVX 使用额外寄存器增加发热,CPU 可能反而会降频工作。建议测试后选择。
关于CUDA程序
v0.41 版本的综合安装包内提供了多种CUDA程序,选择判据如下:
- CUDA 2.3(最低驱动190.38):仅用于老显卡,几乎是万能的。推荐用于8xxx 系列,9xxx 系列,GTX 200 系列等不支持费米/开普勒架构的小显存版本(256MiB)显卡。不兼容费米/开普勒架构。
- CUDA 3.2(最低驱动263.06):“存货”,完全万能,支持费米/开普勒架构。推荐用于8xxx 系列,9xxx 系列,GTX 200 系列等显卡的较大显存版本(300+MiB)。
- CUDA 4.2(最低驱动301.48):推荐用于费米架构(GTX 4xx~GTX 5xx),可以获得极大的性能提升。
- CUDA 5.0(最低驱动306.23):推荐用于开普勒/麦克斯韦架构(GTX 6xx+),可以获得极大的性能提升。
在优化程序下载网页也提供这种CUDA优化:
- CUDA 2.2(最低驱动185.85):“老存货”,为无法更新驱动的用户设计。不兼容费米/开普勒架构。
调优配置
本项目的运算程序和数据文件位于 <BOINC数据目录>/projects/setiathome.berkeley.edu 内。请首先阅读GPU 计算#性能考量。
CUDA程序设置
x41zc或以上的CUDA程序在其安装目录会创建一个mbcuda.cfg,用于自定义程序。(用记事本或类似程序打开编辑)
参数
- processpriority 进程优先级,有'belownormal' (默认), 'normal', 'abovenormal'(推荐), or 'high'(刷分用)四个选项。
- pfblockspersm 每个处理器的搜索运行数量,取值1~16,CUDA3.2或更低版本默认为1,CUDA4.0默认为4,高端卡建议适当加大。
- pfperiodsperlaunch 每次内核启动后信号搜索的最大周期,取值1~1000,默认为100
文件中的分号“;”会将内容加载为注释(即不用),删除后就会激活。
对于CUDA3.2以上的程序,允许自定义每个GPU的参数,其中[mbcuda]表示通用设置,形如[busxsloty]表示以下的一段是X控制器Y槽上面的显卡。
OpenCL程序设置
可以通过编辑 cmdline_程序名代号.txt 指定命令行参数来改变优先级和其他的计算细节。要让 OpenCL 各程序使用高优先级运行,只需在这些文件中写入 -hp。
OpenCL 程序有类似 CUDA 的搜索并行度设置,请参阅README给出的例子设置命令行。
勘误:Intel 的 MB 程序对于高端卡有 oclfft_tune_wg 设置 512 的建议,实际上最大只能使用 256。
其他
- Lunatics Team 发布了 AstroPulse ATI/AMD 纯GPU 和 GPU+CPU 混合优化程序(Win),点击这里查看详情。
- Lunatics Team 发布了 MultiBeam ATI OpenCL 优化程序发布(Win),点击这里查看详情。
附录I:使用Intel显卡计算
现有的优化程序版本(v0.43)和官方服务器均已经在安装向导中提供使用 Intel 显卡的选项,无需冒险这么处理。
用法:
- 加入SETI@home beta项目,使用支持OpenCL的Intel GPU下载一个WU。(需要BOINC7.0+)
- 进入BOINC的数据目录(一般在AppData一类的位置),进入Project子目录,找到带有Intel GPU字样的程序并复制到SETI@home的目录。
- 尝试改写app_info.xml(如果你先安装了优化程序的话):
问题处理
为了防止你的程序被删除,可以尝试事先复制走优化程序(不需要目录下其他文件夹,只要孤立的文件——必须包括app_info),卸载优化再放回。
附录II:进一步提高处理效率
如果你有空有耐心敢尝试,你可以让自己的处理效率更高一点。
自行编译程序
- 下载源代码:http://lunatics.kwsn.net/index.php?module=Downloads;catd=2
- 准备编译工具,你主要需要gcc,g++,cmake以及各个GNU lib(Windows下可以使用MinGW和CMake,根据报错log找需要的组件。)
- 进行编译,使用g++或gcc时你可以加入参数 -march=native -mtune=native -O3 自动利用CPU检测到的指令集并进行优化。对于clang编译器,-O4 会带来更高效率。
- 理论上使用 -Ofast 效率更高(主要是因为 -ffast-math 去除少量检查后带来的浮点提升),然而可能导致计算错误。
- 使用 -flto 可能换来一定程度的性能提升。使用 -fpgo 可令程序编译完后运行一次记录常用函数并使编译器重点优化。