|
|
本帖最后由 金鹏 于 2020-9-29 18:31 编辑
目前来看帕斯卡显卡提升巨大,1070TI跑1343X出了160万+PPD绝对甜点,1080跑134XX出了160+万,1070跑1343X出了120+万
最惊喜的是1080TI跑出了260-280万PPD,提升幅度达到63%
2080TI一直爆包中,估计是超频过度,适当降低频率后稳定在420万PPD,提升幅度20%不如帕斯卡
PS:超频的显卡适当降频保持稳定,并将驱动版本更新至较新版本
TOGETHER WE ARE EVEN MORE POWERFUL: GPU FOLDING GETS A POWERUP WITH NVIDIA CUDA SUPPORT!September 28, 2020CUDA support comes to Folding@home to give NVIDIA GPUs big boosts in speed, and you don’t have to do anything to activate it! GPU Folders make up a huge fraction of the number-crunching power power of Folding@home, enabling us to help projects like the COVID Moonshot open science drug discovery project evaluate thousands of molecules per week in their quest to produce a new low-cost patent-free therapy for COVID-19.
https://youtu.be/VnyaAmM1nhE
The COVID Moonshot (@covid_moonshot) is using the number-crunching power of Folding@home to evaluate thousands of molecules per week, synthesizing hundreds of these molecules in their quest to develop a patent-free drug for COVID-19 that could be taken as a simple 2x/day pill.As of today, your folding GPUs just got a big powerup! Thanks to NVIDIA engineers, our Folding@home GPU cores—based on the open source OpenMM toolkit—are now CUDA-enabled, allowing you to run GPU projects significantly faster. Typical GPUs will see 15-30% speedups on most Folding@home projects, drastically increasing both science throughput and points per day (PPD) these GPUs will generate. 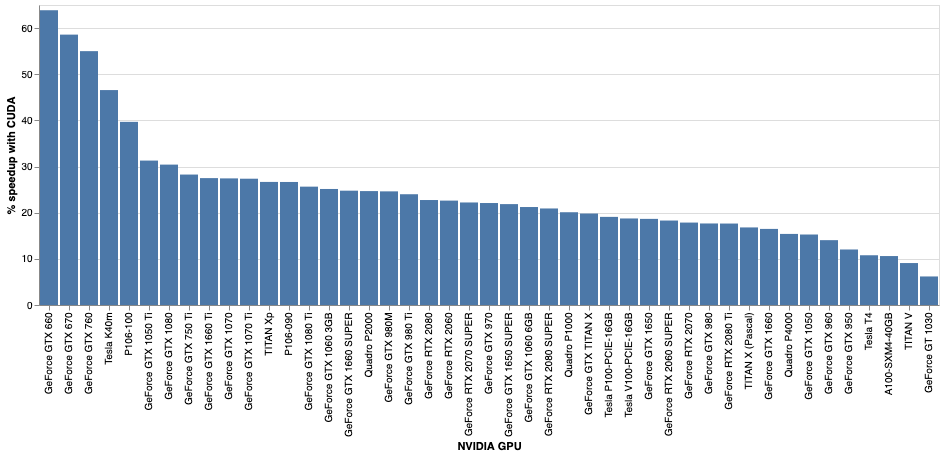 GPU speedups for CUDA-enabled Folding@home core22 on typical Folding@home projects range from 15-30% for most GPUs with some GPUs seeing even larger benefits. GPU speedups for CUDA-enabled Folding@home core22 on typical Folding@home projects range from 15-30% for most GPUs with some GPUs seeing even larger benefits.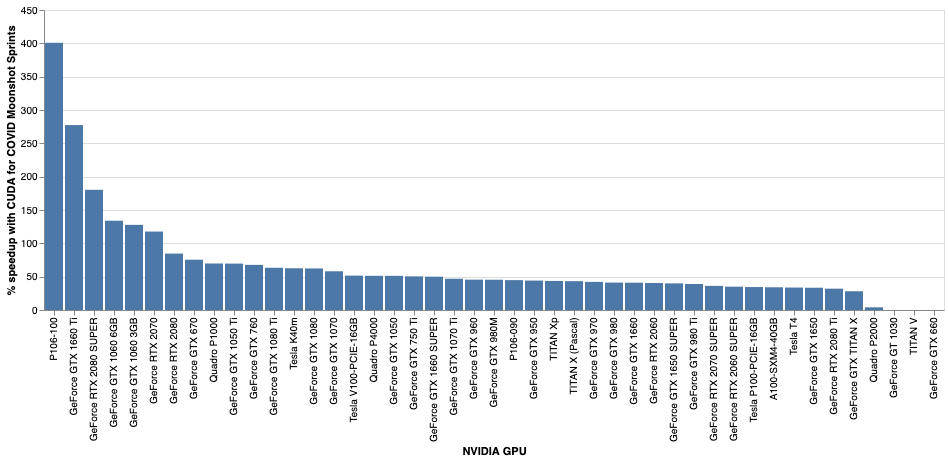 GPU speedups for CUDA-enabled Folding@home core22 on COVID Moonshot projects—which use special features of OpenMM to help identify promising therapeutics—range from 50-400%! GPU speedups for CUDA-enabled Folding@home core22 on COVID Moonshot projects—which use special features of OpenMM to help identify promising therapeutics—range from 50-400%!To see these speed boosts, you won’t have to do anything—the new 0.0.13 release of core22 will automatically roll out over the next few days on many projects, automatically downloading the CUDA-enabled version of the core and CUDA runtime compiler libraries needed to accelerate our code. If you have an NVIDIA GPU, your client logs will show that the 0.0.13 core will attempt to launch the faster CUDA version. 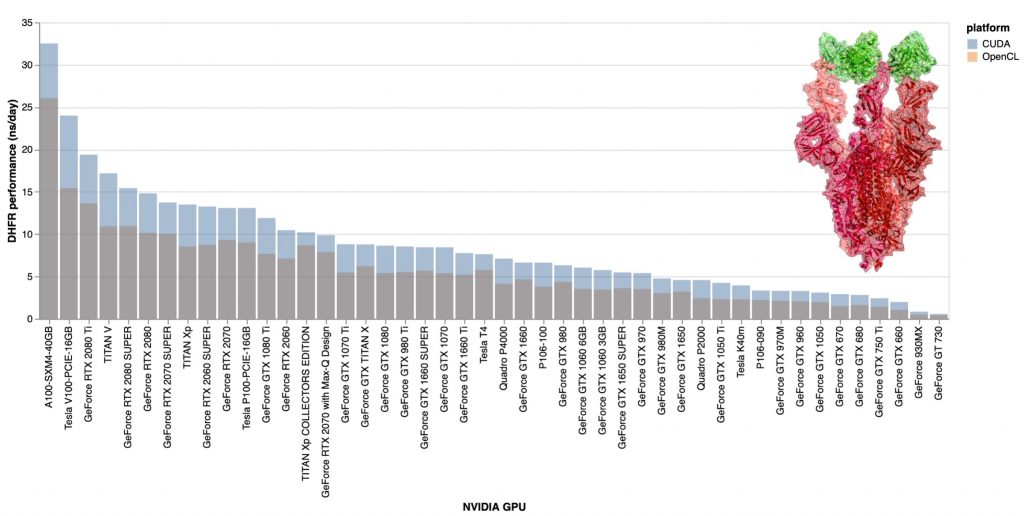 Folding@home core22 0.0.13 performance benchmark for the largest system ever simulated on Folding@home—the SARS-CoV-2 spike protein (448,584 atoms)—with PME electrostatics and 2 fs timestep. Folding@home core22 0.0.13 performance benchmark for the largest system ever simulated on Folding@home—the SARS-CoV-2 spike protein (448,584 atoms)—with PME electrostatics and 2 fs timestep.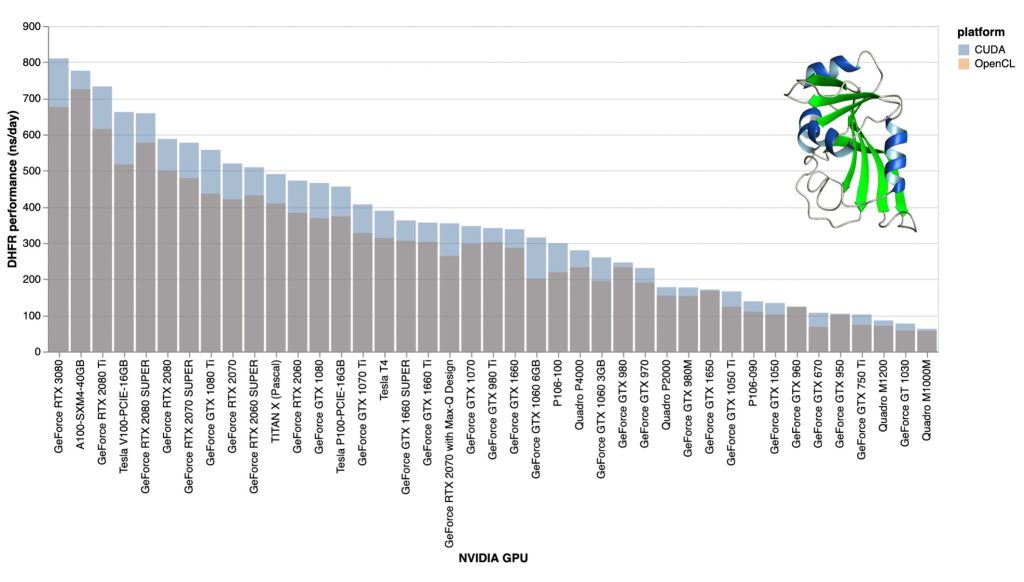 Folding@home core22 0.0.13 performance benchmark (higher ns/day is more science per day!) for a small system—the DHFR benchmark (23,558 atoms)—with PME electrostatics and 4 fs timesteps using a BAOAB Langevin integrator. Folding@home core22 0.0.13 performance benchmark (higher ns/day is more science per day!) for a small system—the DHFR benchmark (23,558 atoms)—with PME electrostatics and 4 fs timesteps using a BAOAB Langevin integrator.To get the most performance out of the new CUDA-enabled core, be sure to update your NVIDIA drivers! There’s no need to install the CUDA Toolkit. While core22 0.0.13 should automatically enable CUDA support for Kepler and later NVIDIA GPU architectures, if you encounter any issues, please see the Folding Forum for help in troubleshooting. Both Folding@home team members and community volunteers can provide help debug any issues. Besides CUDA support, core22 0.0.13 includes a number of bugfixes and new science features, as well as more useful information displayed in the logs. We’re incredibly grateful to all those that contributed to development of the latest version of the Folding@home GPU core, especially: - Peter Eastman, lead OpenMM developer (Stanford)
- Joseph Coffland, lead Folding@home developer (Cauldron Development)
- Adam Beberg, Principal Architect, Distributed Systems (NVIDIA) and original co-creator of Folding@home nearly 21 years ago!
https://youtu.be/E98hC9e__Xs
In addition, we couldn’t have brought you these improvements without the incredible effort of all of the Folding@home volunteers who helped us test many builds, especially PantherX, Anand Bhat, Jesse_V, bruce, toTOW, davidcoton, mwroggenbuck, artoar_11, rhavern, hayesk, muziqaz, Zach Hillard, _r2w_ben, bollix47, joe_h, ThWuensche, and everyone else who tested the core and provided feedback. core22 0.0.13 in BETA testing : CUDA support at last![size=1.3em]After a lot of work from a large number of awesome folks, we've just rolled out core22 0.0.13 to BETA!
Currently, we're only testing project 17102, which is a collection of different RUNs (RUN0 through RUN17) that test different workloads in short WUs for benchmarking and stability analysis.
As a reminder, you can set yourCODE:
SELECT ALLclient-type
toCODE:
SELECT ALLbeta
to run through BETA projects (like 17102).
After that, we'll test more broadly in BETA projects before the full announce.
Full release notes are below:
New features
- 0.0.13 adds support for CUDA for NVIDIA GPUs! This enables NVIDIA GPUs to run ~25% faster on normal projects and up to 50-100% faster for COVID Moonshot free energy sprints. Expect to see noticeably lower time per frame (TPF) numbers for these projects with significantly higher points per day (PPD). The core will fall back to OpenCL if CUDA cannot be configured.
- More useful debugging information is printed in the client logs when the CUDA or OpenCL platforms cannot be configured.
- The core now bundles dynamic libraries instead of compiling libraries statically to permit various platforms and plugins to be loaded dynamically. This was essential for enabling CUDA support.
- The OpenCL driver version is now reported in the client logs
- Checkpoints are now reported in the client logs
- The final integrator state is returned at the end of the WU, allowing for more complex simulation schemes that employ OpenMM CustomIntegrator
Bugfixes
- Several OpenMM bugfixes for AMD GPUs were incorporated.
- Temperature monitor warnings have been removed.
- Requesting the core to shut down during core initialization should now be handled more gracefully
- On older clients, `-gpu` is interpreted as a synonym for `-opencl-device`, and a warning to upgrade the client is issued
Known issues
- We are noticing that some NVIDIA linux beta drivers sometimes fail when using the OpenCL platform with the Windows Subsystem for Linux 2 (WSL2) with
CODE: SELECT ALLERROR:exception: Error initializing context: clCreateContext (218)
and are actively working with NVIDIA to track down and fix this issue. In the meantime, we hope the CUDA support will provide a work-around for this issue. Please post here if you encounter this issue so we can work with you to more quickly test a fix. - Older NVIDIA GPUs (Fermi and older) may not be able to make use of CUDA, but will fall back to OpenCL instead
Acknowledgments
Enormous thanks to the following people for their help in producing the latest core:
- Peter Eastman, lead OpenMM developer (Stanford)
- Joseph Coffland, lead Folding@home developer (Cauldron Development)
- Adam Beberg, Principal Architect, Distributed Systems (NVIDIA) (and original co-architect of Folding@home nearly 21 years ago!)
Huge thanks to the extremely patient Folding@home volunteers who helped us test many builds of this core, especially PantherX, Anand Bhat, Jesse_V, bruce, toTOW, davidcoton, mwroggenbuck, artoar_11, rhavern, hayesk, muziqaz, Zach Hillard, _r2w_ben, bollix47, joe_h, ThWuensche, and everyone else who tested the core and provided feedback. Re: core22 0.0.13 in BETA testing : CUDA support at last! by Jesse_V » Sun Sep 20, 2020 9:39 am by Jesse_V » Sun Sep 20, 2020 9:39 am
During our testing, we've also been able to perform some benchmarking between Windows -> Linux and OpenCL -> CUDA. While a ~20-25% performance boost is fairly common for Linux when compared to Windows, there's a very big boost when comparing OpenCL on WIndows to CUDA on Linux. You can see this in the time per frame (TPF) for specific projects. For example, on COVID Moonshot free energy calculation projects:
p13426 at 10% in Windows 10 on GTX 1080 Ti running OpenCL: TPF of 1:57
p13426 at 10% in Windows 10 on GTX 1080 Ti running CUDA: TPF of 1:16
p13426 at 10% in Debian on GTX 1080 Ti running OpenCL: TPF of 1:34
p13426 at 10% in Debian on GTX 1080 Ti running CUDA: TPF of 0:59
So if Windows-OpenCL is our baseline, then on this project, the speed improvements are:
Windows-CUDA: +53%
Debian-OpenCL: +24%
Debian-CUDA: +98%
CUDA average: +75%
The core will attempt to use CUDA when available. This translates into a very significant gain in PPD, as Adam Beberg found for another project across different Nvidia hardware in Linux:
TPF 73s - GTX 1080Ti running OpenCL/ 1.554 M PPD
TPF 57s - GTX 1080Ti running CUDA / 2.253 M PPD
TPF 49s - RTX 2080Ti running OpenCL/ 2.826 M PPD
TPF 39s - RTX 2080Ti running CUDA / 3.981 M PPD
TPF 36s - RTX 3080 running OpenCL / 4.489 M PPD
TPF 31s - RTX 3080 running CUDA / 5.618 M PPD
Finally, I'd like to highlight that core22 v0.0.13 currently seems incompatible with the pocl-opencl-icd package in Ubuntu, which is depend on libpocl2. These package is not necessary to run F@h, but if you have them installed, please remove them before running the core. Other than that, if the core segfaults at startup or fails to start or run in any way, please post below!


|
|


 发表于 2020-9-20 10:26:52
发表于 2020-9-20 10:26:52
 发表于 2020-9-21 11:46:33
发表于 2020-9-21 11:46:33


 发表于 2020-9-22 09:59:02
发表于 2020-9-22 09:59:02
 发表于 2020-9-22 20:31:20
发表于 2020-9-22 20:31:20