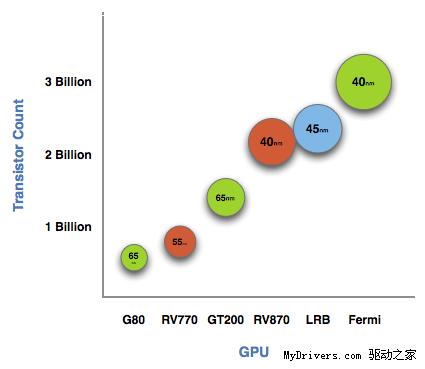
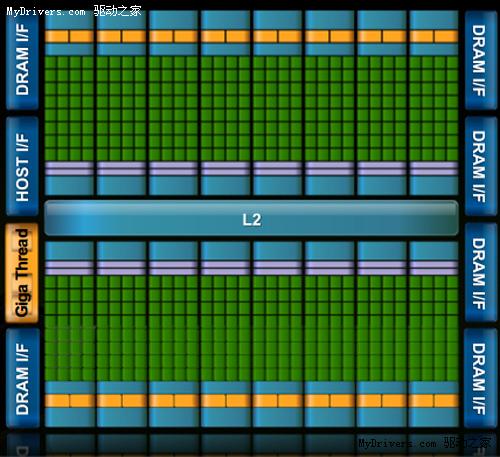
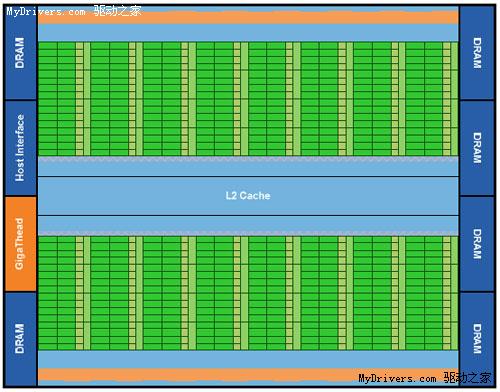
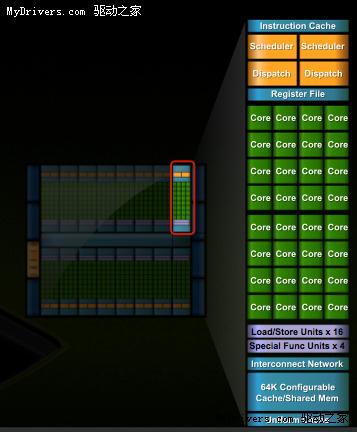
使用道具 举报
原帖由 zglloo 于 2009-10-3 17:20 发表 从过去的项目来看 似乎每次对于A卡的计算优化更多些
本版积分规则 发表回复 回帖并转播 回帖后跳转到最后一页
Archiver|手机版|小黑屋|中国分布式计算总站 ( 沪ICP备05042587号 )
GMT+8, 2025-5-5 05:04
Powered by Discuz! X3.5
© 2001-2024 Discuz! Team.


 发表于 2009-10-1 12:32:24
发表于 2009-10-1 12:32:24
 。
。
 发表于 2009-10-1 16:12:17
发表于 2009-10-1 16:12:17